Korean
Korean
IndexFiguresTables |
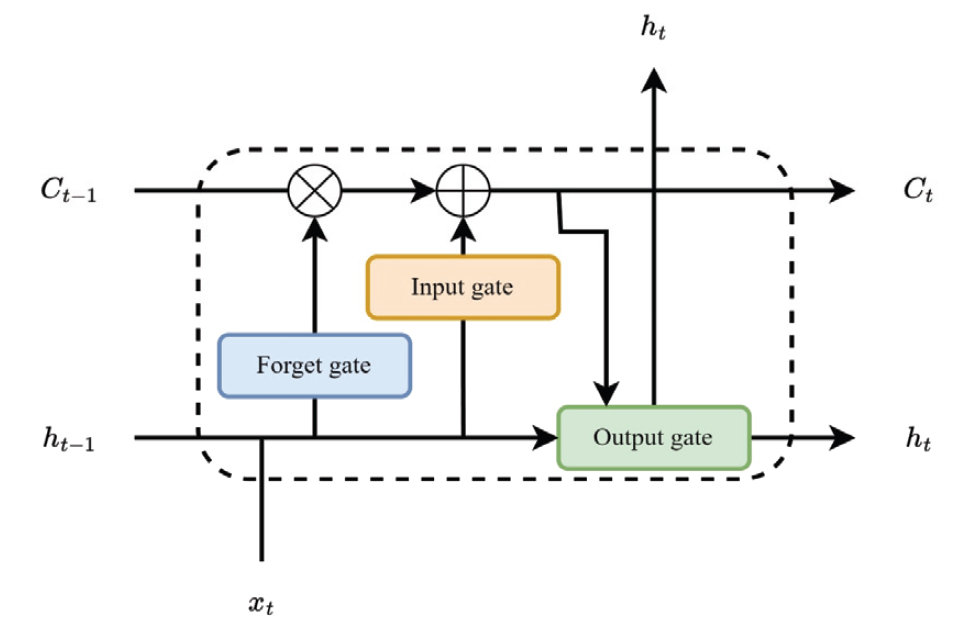
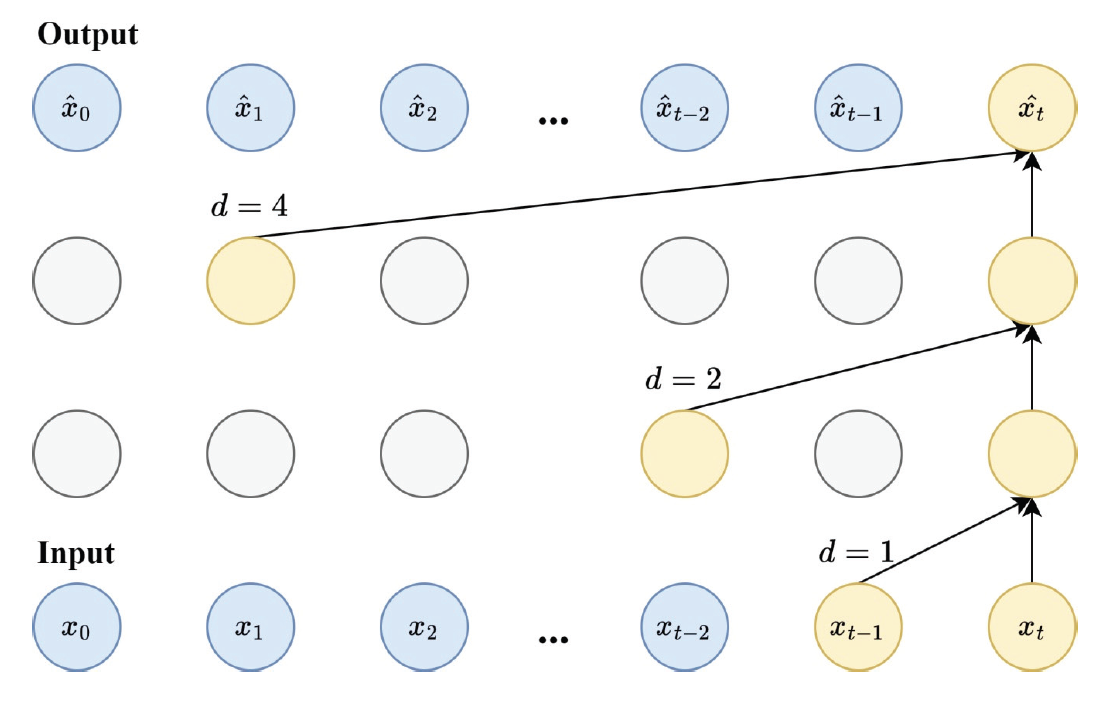
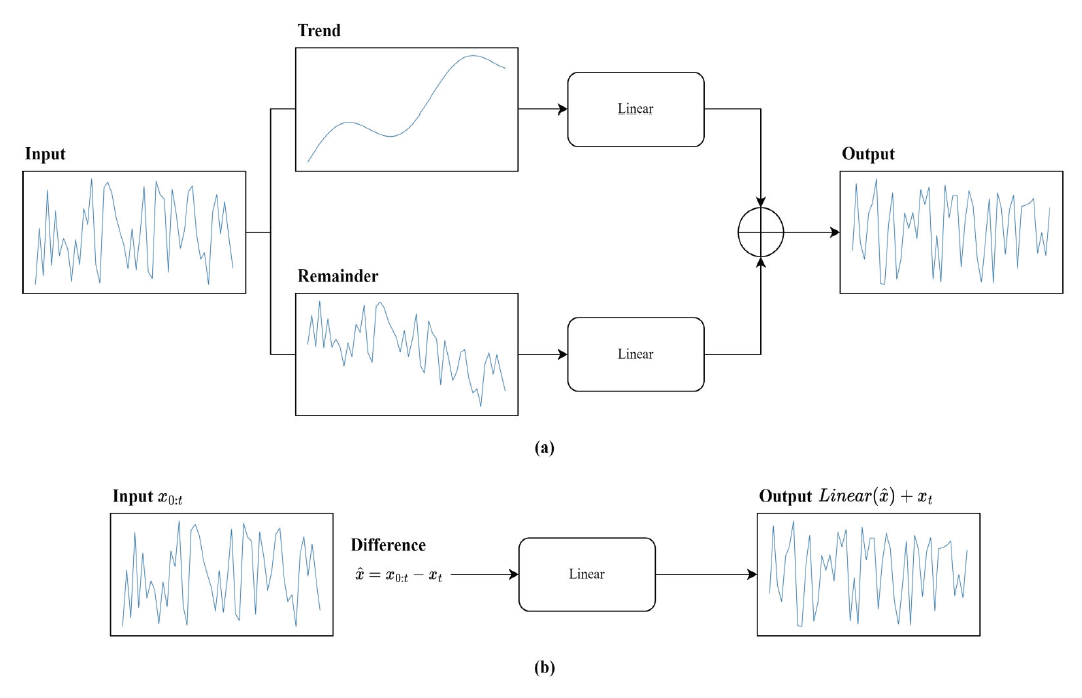
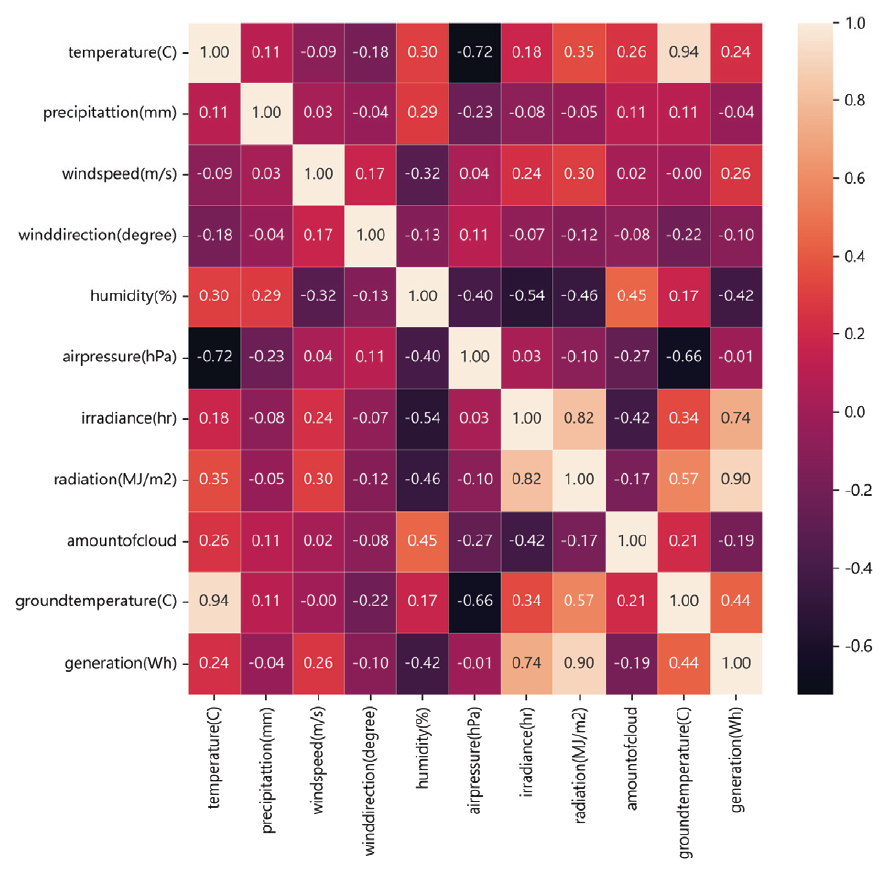
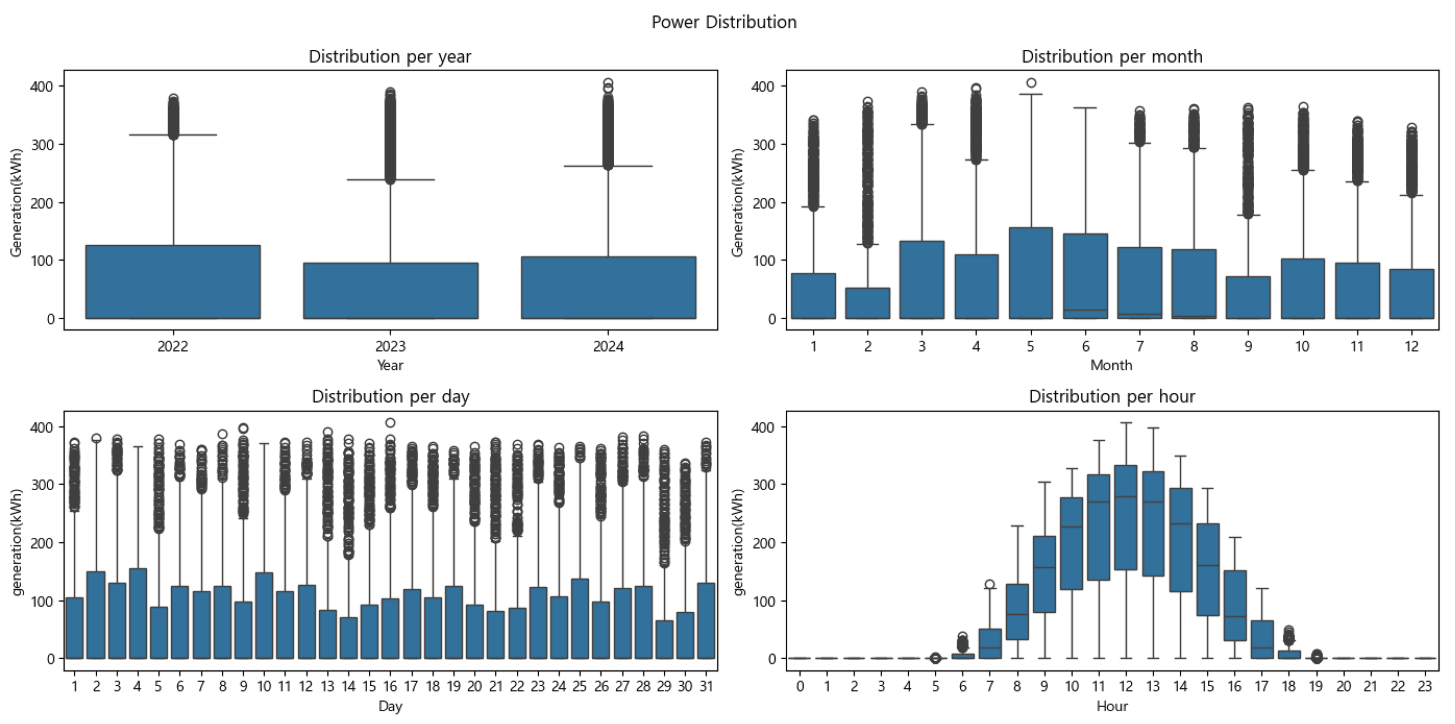
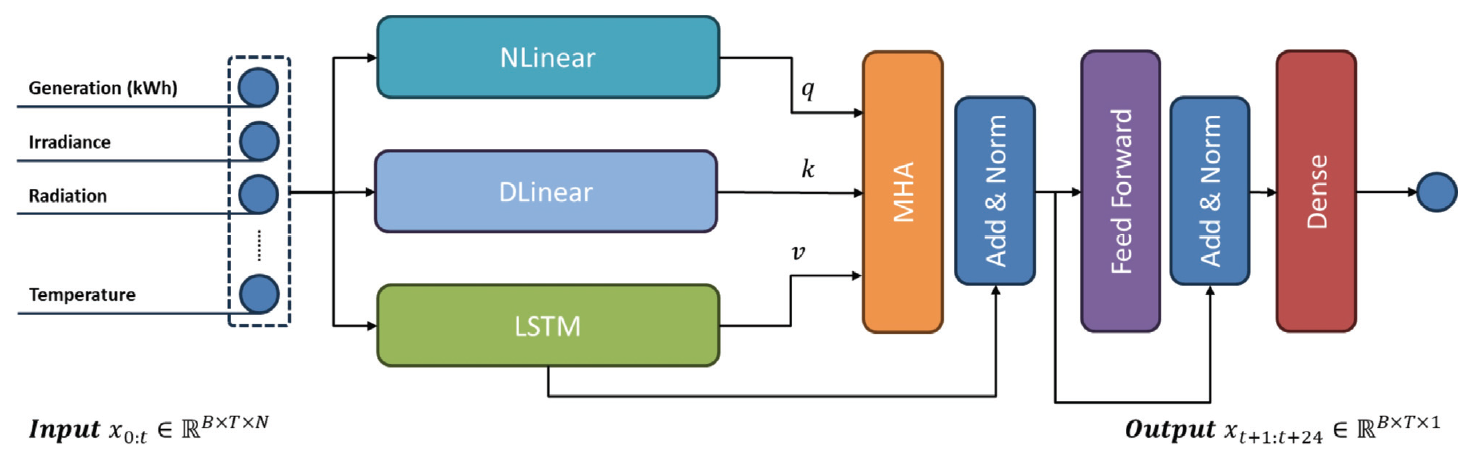
Hyeonseok Jin† , David J. Richter†† , MD Ilias Bappi†† and Kyungbaek Kim†††Solar Power Generation Forecasting Using a Hybrid LSTM-Linear Model with Multi-Head AttentionAbstract: Due to the negative impact on the environment, the demand for solar energy, which can effectively replace fossil fuels, is increasing. In order to operate solar energy efficiently, deep learning has been used recently to predict future power generation, but it is still a challenge to provide accurate predictions because the power generation greatly depends on external factors such as weather and time of day. In this paper, we propose a hybrid model that combines LSTM and Linear models using Multi-Head Attention to provide mor e accurate predictions. The proposed model can improve prediction accuracy and learn richer time series features because each Linear model can capture trends and irregularities in time series features. We conducted extensive experiments, and the results showed that the proposed model outperformed other prediction models by about 10%, and the ablation study confirmed that combining three models based on Multi-Head Attention is the most effective way to consider trends and irregularities. Keywords: Solar Power Prediction , Power Generation , Prediction , Time series , Deep Learning 진현석†, David J. Richter††, MD Ilias Bappi††, 김경백†††멀티 헤드 어텐션이 적용된 하이브리드 LSTM-Linear 모델을 이용한 태양광 발전량 예측요 약: 환경에 미치는 부정적인 영향으로 인해 화석 연료를 효과적으로 대체할 수 있는 태양광 에너지에 대한 수요가 증가하고 있다. 태양광 에너지를 효율적으로 운영하기 위해 최근 딥러닝을 사용하여 미래의 발전량을 예측하고 있으나, 발전량은 날씨, 시간대와 같은 외부 요인에 크게 의존하기 때문에 정확한 예측을 제공하는 것은 여전히 도전적인 과제이다. 본 논문에서는 보다 정확한 발전량 예측을 제공하기 위해 멀티 헤드 어텐션을 사용하여 LSTM과 선형 모델을 결합한 하이브리드 모델을 제안한다. 제안된 모델은 각 선형 모델이 시계열 특징의 추세와 불규칙성을 포착할 수 있기 때문에 예측 정확도를 개선하고 더 풍부한 시계열 특징을 학습할 수 있다. 광범위한 실험을 수행한 결과, 제안된 모델은 다른 예측 모델보다 약 10% 정도 성능이 우수하였으며, 절제 연구를 통해 멀티 헤드 어텐션에 기반하여 세 가지 모델을 결합하는 것이 추세와 불규칙성을 고려하는 데 가장 효과적인 방법임을 확인하였다. 키워드: 태양광 발전량 예측, 발전량, 예측, 시계열, 딥러닝 1. IntroductionClimate change and global warming are critical global challenges that demand immediate and innovative solutions. Traditional energy sources such as coal and oil significantly contribute to environmental degradation, emphasizing the urgent need for sustainable energy alternatives. Renewable energy sources, including solar, wind, and water, have emerged as essential components for a sustainable future. Solar energy, in particular, has gained widespread adoption due to its potential for clean and efficient power generation. However, its reliance on external factors such as solar radiation, time of day, and weather conditions introduces variability and unpredictability in power generation, posing challenges for effective integration into the power grid [1]. The International Energy Agency (IEA) estimates that photovoltaic (PV) systems will achieve a peak power capacity of 1200 GW by the end of 2023 [2]. These systems, commonly installed in open areas, on rooftops, and in solar power plants, offer a promising path to reducing dependence on traditional energy sources. Despite their advantages, the intermittent nature of solar power generation disrupts regular operations, complicating energy distribution and grid stability. For instance, fluctuating solar radiation and environmental conditions can lead to energy deficits or surpluses, necessitating advanced forecasting systems to optimize energy storage and usage [3]. Reliable forecasting of solar power generation is essential for ensuring grid stability and maximizing the benefits of renewable energy. Unlike traditional power plants that offer predictable energy outputs, solar energy systems depend on dynamic environmental conditions, making accurate forecasting crucial for energy management. Effective prediction of energy generation enables better planning for storage during surplus periods and ensures energy availability during low-generation intervals [4]. Recent advancements in deep learning have demonstrated significant potential in addressing the challenges of solar power forecasting. Time series forecasting techniques such as Long Short-Term Memory (LSTM) networks, linear models, and attention mechanisms have proven effective in capturing complex patterns and irregularities in solar power data. These approaches surpass traditional methods like physical and statistical models, which often struggle with non-linearities and variability in data [5]. To address these challenges, this study proposes a hybrid deep learning model combining LSTM and linear models with a multi-head attention mechanism. The hybrid model leverages the strengths of each component: LSTM networks capture short-term dependencies and irregular patterns, linear models identify long-term trends, and the multi-head attention mechanism enhances feature extraction by focusing on critical temporal relationships. By integrating these techniques, the proposed model achieves superior forecasting performance, offering a reliable solution for managing the complexities of solar power generation [6]. Extensive experiments conducted in this study demonstrate that the hybrid model outperforms existing forecasting approaches by approximately 10% in prediction accuracy. Additionally, ablation studies validate the effectiveness of integrating multi-head attention with LSTM and linear models, highlighting its ability to capture trends and irregularities in time series data. These findings underscore the potential of the proposed hybrid approach to advance solar energy forecasting and enhance its integration into the energy grid [7-8]. The main contributions of this research work are as follows: · We propose a novel hybrid model that integrates LSTM networks and linear models with a multi-head attention mechanism to enhance solar power generation forecasting. · The hybrid model effectively captures both short-term irregularities and long-term trends in time series data, addressing the inherent variability of solar power generation. · By leveraging the multi-head attention mechanism, the model learns richer temporal features and focuses on critical patterns in historical data for improved prediction accuracy. · Extensive experiments demonstrate that the proposed hybrid model outperforms existing stateof- the-art prediction methods by approximately 10% in forecasting accuracy. · Ablation studies validate the effectiveness of combining LSTM, linear models, and attention mechanisms, highlighting the contributions of each component to the overall performance. The rest of this article is organized as follows: Section 2 reviews the related works, followed by a comprehensive description of background knowledge and the proposed methodology in Sections 3 and 4. Section 5 presents the experimental results and analysis, while Section 6 providing key insights and discusses future directions. Finally, the last section, Section 7 concludes the study. 2. Related WorksWith the unpredictability of green energy, e.g. solar power, when compared with energy sources such as nuclear, oil, and coal for example, the need for methods that can forecast the power output becomes clear. As such, this problem has received a lot of attention in recent years, some of which will be introduced in this section. Prema et al. [9] provide a lot of insight into the field of solar power generation prediction in their review paper, with a focus on datasets, models used, as well as common performance metrics. The paper reviews not only solar power, but also wind power applications. The paper identifies irradiance as the feature with the greatest impact on prediction performance. The authors state that deep learning technologies have shown great results recently, but point out that short-term prediction (up to 1 or 2 days) is recommended. Lastly the study found that the Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), and Symmetric Mean Average Percentage Error (SMAPE) are the most commonly used metrics. Shin et al. [10] performed solar power generation forecasting using deep learning techniques on a dataset that was collected in Mokpo in Korea. The data was collected over 2 years between 2013 and 2015. The dataset included solar irradiance and solar radiation and the models trained on said data were based on ANFIS, DNN, Recurrent Neural Network (RNN) and LSTM. The authors’ results showcase that the RNN model managed to perform better than the other models used in this work based on the metrics used (RMSE, MAE, BIAS, and COR). Park et al. [11] analyze the performance of BiLSTM and SHAP-based XAI techniques in solar power forecasting. This work also uses power data obtained in Korea, from different plants across the country. The integration of XAI allows researchers to better understand the trained models and, therefore, also allows them to update the model based on that, overcoming the common “black-box” problem that Deep Learning (DL) models often pose. Khan et al. [12] incorporated attention mechanisms into their DL model. The dual stream network utilizes both CNN and GRU methods, allowing the model to capture both spatial and temporal relations. This is then combined with a self attention block to further learn relations present in the data. Three datasets were used during the ex periments and MSE, RMSE, a nd MAE i ndicate that t he 2. Related WorksWith the unpredictability of green energy, e.g. solar power, when compared with energy sources such as nuclear, oil, and coal for example, the need for methods that can forecast the power output becomes clear. As such, this problem has received a lot of attention in recent years, some of which will be introduced in this section. Prema et al. [9] provide a lot of insight into the field of solar power generation prediction in their review paper, with a focus on datasets, models used, as well as common performance metrics. The paper reviews not only solar power, but also wind power applications. The paper identifies irradiance as the feature with the greatest impact on prediction performance. The authors state that deep learning technologies have shown great results recently, but point out that short-term prediction (up to 1 or 2 days) is recommended. Lastly the study found that the Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), and Symmetric Mean Average Percentage Error (SMAPE) are the most commonly used metrics. Shin et al. [10] performed solar power generation forecasting using deep learning techniques on a dataset that was collected in Mokpo in Korea. The data was collected over 2 years between 2013 and 2015. The dataset included solar irradiance and solar radiation and the models trained on said data were based on ANFIS, DNN, Recurrent Neural Network (RNN) and LSTM. The authors’ results showcase that the RNN model managed to perform better than the other models used in this work based on the metrics used (RMSE, MAE, BIAS, and COR). Park et al. [11] analyze the performance of BiLSTM and SHAP-based XAI techniques in solar power forecasting. This work also uses power data obtained in Korea, from different plants across the country. The integration of XAI allows researchers to better understand the trained models and, therefore, also allows them to update the model based on that, overcoming the common “black-box” problem that Deep Learning (DL) models often pose. Khan et al. [12] incorporated attention mechanisms into their DL model. The dual stream network utilizes both CNN and GRU methods, allowing the model to capture both spatial and temporal relations. This is then combined with a self attention block to further learn relations present in the data. Three datasets were used during the experiments and MSE, RMSE, and MAE indicate that the proposed model achieves the highest performance under the author's conditions. Polasek et al. [13] also present a hybrid model to solve the problem of solar power forecasting. In this case a U-Net structure in combination with the ResNet CNN model were used. Pre-processing techniques were applied to solve issues present in uncertain datasets. The dataset, which was published as part of this paper, contains 16 power plants’ data over a year's time. After evaluation, the authors present their hybrid model as the best performing model on the dataset. Shamshirband et al. [14] survey the field in their paper. The paper also reviews wind energy. Based on the data provided in the paper, it seems as if wind power has garnered more research interest. The authors stress the importance of enough and high quality data to train reliable models. Common metrics, methods and workflows are presented in the paper, as are metrics. According to the authors, RMSE is recommended as a metric. Dairi et al. [15] make use of variational Auto Encoder (VAE) based deep learning models. This model was compared to RNN, LSTM, Bidirectional LSTM, Convolutional LSTM network (ConvLSTM), GRU, stacked autoencoder (SAE), restricted Boltzmann machine (RBM), logistic regression and support vector regression (SVM). The VAE based methods, as proposed by the authors, managed to outperform all other models in their experiments. Also noteworthy is the pre-processing applied to the dataset, as the authors used normalization to range all input values between 0 and 1. Chang et al. [16] propose TESDL. TESDL stands for Traditional Encoder Single Deep Learning. TESDL was compared to SVM, CNN and LSTM-CNN in the paper and has proven to perform better. This paper too states the difference between long and short-term forecasting, with short-term forecasting being much more feasible and as such much more accurate. TESDL managed to generate good results until about 50 steps ahead, after which it started to fall off. Zazoum et al. [17] did not use DL methods, but rather studied ML for the field. Different variations of SVM and gaussian process regression (GPR) were included in this work, with Matern 5/2 GPR achieving the best performing model. Cubic SVM, on the other hand, was the worst performing model. The results obtained in this work showcase that ML models, which are model more light-weight than computationally much heavier DL methods, can also generate well performing predictors. Alharkan et al. [18] present a dual stream CNN-LSTM model with s elf-attention. T he C NN model e x cels in learning spatial relations, the LSTM excels in learning temporal relations and the self-attention block is meant to learn relations within the dataset. The DKASC Alice Spring dataset was used in this work to train the model and CNN, LSTM, GRU, CNNLSTM, CNNGRU for comparison. The comparative study showed that the proposed model (DSCLANet) managed the highest performance. Alkandari et al. [19] built a Ensemble model for solar power generation prediction that uses DL methods in combination with statistical methods to rely on the strength of both approaches. The Machine Learning and Statistical Hybrid Model (MLSHM) uses LSTM, GRU and Auto LSTM as the DL methods of choice. Results show that the ensemble methods managed to outperform the DL methods without ensembleing. Shouman et al. [20] use and compare neural networks, SVM, Random Forest (RF), and gradient boosting to forecast solar power generation. To pre-process the data, the authors used normalization as well as feature selection methods to identify and use only the most useful features, while discarding features that might negatively impact the models performance. Here MSE and RMSE were used for evaluation. In their use-case comparative study gradient boosting managed to outperform the other models. Lee et al. [21] used a dataset recorded in Taiwan that they then normalized for pre-processing. The data was collected for about a year and 3 months between late 2018 and early 2020. The dataset was then tested on RNN, LSTM and GRU models, both uni and bi-directional for each of them. The results have shown that in this scenario the Bidirectional-GRU model managed to perform better than any of the other models tested. Barrera et al. [22] test a number of different DL models to predict future solar power generation. For this dense layers were compared with stratified layers, models with 1 hidden layer were compared to models with 2, and global radiation was compared to decomposed radiation. The model stratified layers, 2 hidden layers and decomposed radiation managed to perform better than the other models tested. Kim et al. [23] showcase a multi-step approach to power prediction where they first train a model to predict the solar irradiance, to then use said predicted irradiance value to train and predict a solar power generation model with it. Random Forest Regression (RFR), Support Vector Regression (SVR), and gradient boosting were tested for this task. The authors explain that unexpected weather events can cause high inaccuracy in a model's prediction, even if the models otherwise achieves very high accuracy and even models that are otherwise weather aware. RFR was the best performing model trained in this work. 3. BackgroundIn this section, we introduce the concepts and features of LSTM [24], Temporal Convolutional Network (TCN) [25], and Linear models [26], which are widely used in the field of time series prediction. 3.1 LSTMRNN have difficulty capturing long-term time series features due to gradient vanishing when the length of input data becomes too long. LSTM were proposed to solve this problem and effectively solve it by utilizing the Cell and Gate structure. LSTM consist of a Cell state that updates and transmits information, an Input gate that stores new information, a Forget gate that removes unimportant information, and an Output gate that determines the information to be output. The Cell state [TeX:] $$C_{t-1}$$ is updated by passing the information [TeX:] $$h_{t-1}$$ of the previous time point and the input value [TeX:] $$x_t$$ of the current time point through the Forget gate and the Input gate, and the updated Cell state [TeX:] $$C_t$$ and the Hidden state [TeX:] $$h_t$$ are passed through the Output gate to generate the output value of the current time point. 3.2 TCNLSTM overcomes the limitations of existing RNN and shows innovative performance in the time series field, but it has the disadvantage of high computational cost due to its complex structure a nd t aking a long t ime due to i ts sequential nature, which requires waiting until the inference of the previous time point is completed to perform the inference of the next time point. TCN performs parallel operations based on Convolutional Neural Networks (CNNs) and overcomes these shortcomings. In addition, it can capture long-term time series features by adopting Causal padding that uses only data up to the current time point and Dilation structure that gradually increases the interval of the filter, and it enables flexible expansion by increasing the filter size or interval. We will compare our proposed model to TCN. 3.3 Linear ModelsThese models were proposed to question the validity of Transformer [27] based time series prediction models relatively recently, and effectively learn time series features using a simple linear layer consisting of only Fully-Connected Layers (FC). DLinear decomposes the entire input value into a way to return the average value for a specific period and learns each of them to effectively predict data with a trend. NLinear operates by learning the difference by subtracting the last step from the input value and then adding it back to restore it, and effectively predicts irregular data. 4. MethodsIn order to make more accurate solar power generation predictions, we need to consider various external variables that are closely related to solar power generation [28], and we need to be able to capture rapid changes in data [9]. In this paper, we perform predictions using solar power generation data and weather data. We also propose a new hybrid model for accurate solar power generation predictions by merging them. 4.1 Data Collection and PreprocessingIn this paper, we used solar power generation data [29] and weather data [30] in the Ulsan area. Solar power generation data is provided by the Korea Public Data Portal, and includes power generation data collected every hour from April 1, 2022 to June 30, 2024. Weather data is provided by the Korea Meteorological Administration, and includes temperature, precipitation, wind speed, wind direction, humidity, airpressure, irradiance, radiation, amount of cloud, and ground temperature during the same period. First, we measured the correlation between power generation and weather variables to remove unnecessary variables in Fig. 4. radiation, irradiance, surface temperature, humidity, etc. showed high correlations, but precipitation and air pressure showed low correlations and were removed. Next, we performed the task of imputing the missing values in the data. As shown in Fig. 5, the distribution of power generation is greatly affected by the sun, so the distribution varies the most by hour. Therefore, we impute the missing values by the median of each hour to maintain the distribution of the original data. Finally, we reflect the continuity of wind direction and time data. For wind direction, it has a scalar value from 0 to 360, and if used as is, 0 and 360 mean the same direction, but there is a big difference. Time also has a scalar value from 0 to 24, and yesterday 23:00 and today 1:00 represent adjacent dates and times, but there is a big difference. We use (1), and (2) to express the scalar value as a continuous coordinate vector and reflect the continuity.
(1)[TeX:] $$\begin{aligned} & \text { Wind }_x=\cos \left(W_S^*\left(W_D^* \pi / 180\right)\right) \\ & \text { Wind }_y=\sin \left(W_S^*\left(W_D^* \pi / 180\right)\right) \end{aligned}$$
(2)[TeX:] $$\begin{aligned} & D a y_x=\cos \left(T_S^*(2 \pi / S o D)\right) \\ & D a y_y=\sin \left(T_S^*(2 \pi / S o D)\right) \end{aligned}$$[TeX:] $$W_S \text { and } W_D$$ represent wind speed and wind direction, respectively, and [TeX:] $$T_S$$ is a timestamp representing the time in seconds since 00:00 (UTC) on January 1, 1970. Seconds of the Day ([TeX:] $$SoD$$) is a value representing the time elapsed from midnight to the present time, expressing a day in seconds. 4.2 Hybrid Model StructureThe structure of the hybrid model proposed in this paper is as shown in Fig. 6. In order to accurately perform the challenging task of power generation prediction, we learn sequential features as well as extract and reflect trends and irregular features. The input data [TeX:] $$x_{0: t} \in \mathbb{R}^{B \times T \times N},$$ which consists of N weather data and power generation for T hours with batch size B, is learned and features are extracted using three backbone models: LSTM, DLinear, and NLinear. DLinear learns the trend of the input data and extracts features reflecting it, and NLinear learns differences to learn and extract irregular time series features. LSTM learns sequential features and generates an overall prediction value. Each prediction can be expressed as follows (3):
(3)[TeX:] $$\begin{aligned} & O_N=\operatorname{NLinear}\left(x_{0: t}\right) \\ & O_D=\operatorname{DLinear}\left(x_{0: t}\right) \\ & O_L=\operatorname{LSTM}\left(x_{0: t}\right) \end{aligned}$$In addition, to effectively integrate the output of each backbone model, the Multi-Head Attention (MHA) structure is used to distribute it to k parallel heads, each of which performs self-attention tasks. Each head computes a dimension of size [TeX:] $$d_x$$, and MHA can be expressed as follows (4):
(4)[TeX:] $$\begin{aligned} &d_k=d_{\text {model }} / k\\ &M H A(Q, K, V)=\operatorname{softmax}\left(\frac{Q K}{\sqrt{d_k}} V^T\right) \end{aligned}$$The outputs [TeX:] $$O_N \text { and } O_D$$ obtained from NLinear and DLinear generate an attention matrix based on the trend and irregular features of the input data, and are multiplied by the output [TeX:] $$O_L$$ of LSTM to suppress unnecessary features and allow the model to focus on important features. After that, the attention-reflected features are refined through the Feed Forward Network (FFN) based on Multi Layer Perceptron (MLP), and the last Dense layer compresses the features with the size of N into a single power feature. The final output of the model [TeX:] $$x_{t+1: t+24} \in \mathbb{R}^{B \times T \times 1}$$ can be expressed as follows (5):
(5)[TeX:] $$\begin{aligned} & O_{A t t}=\operatorname{LayerNorm}\left(O_L+\operatorname{MHA}\left(O_N, O_D, O_L\right)\right) \\ & O_{F F N}=\operatorname{LayerNorm}\left(O_{A t t}+F F N\left(O_{A t t}\right)\right) \\ & x_{t+1: t+24}=\operatorname{Dense}\left(O_{F F T}\right) \end{aligned}$$The proposed hybrid model can reflect the trend and irregular features captured from linear models in the prediction of LSTM, thereby richly reflecting the features of time series data. In addition, it suppresses unnecessary features by using self-attention technique, and allows the model to focus on important features, enabling robust and accurate prediction. 5. ExperimentsIn order to demonstrate the superiority of the hybrid model proposed in this paper, we conducted comparative experiments with other time series forecasting models. In addition, to ensure the robustness of the experimental results, we conducted a ablation study on the prediction length and the combining method. 5.1 Implementation DetailsThe experiments were conducted on Python 3.9.13, Tensorflow 2.10.1 and Keras 2.10.0 with Intel(R) Core(TM) i7-10700 CPU @ 2.90GHz, RTX 3070 environment in Windows 10 WSL. The batch size is set to 256, and training is performed with the AdamW optimizer with a learning rate of 0.0005 for 100 iterations and the MSE loss function. The dataset is configured to predict the future for 24 hours based on 24-hour input data using the sliding window technique [31], and the value range is normalized to 0 to 1 through Min-Max normalization. Of the total 19,680 data, 17,520 data for 2 years are used for training, and the remaining 2,160 data are divided in half and used for validation and testing, respectively. 5.2 MetricsEvaluation is performed with actual value range by performing denormalization on the predicted values. In addition to Root Mean Squared Error (RMSE) and MAE, mMAPE [32] and R2 are also used as metrics to provide more intuitive indicators. RMSE and MAE represent the difference between the predicted value and the actual value, respectively, and along with mMAPE, the lower the value, the better the prediction quality. mMAPE represents the degree of error in the predicted value as a percentage between 0 and 100. R2 represents the maximum explanatory power of the model, and the higher the value, the better the explanatory power. Each metric for the actual value y and the predicted value [TeX:] $$\hat{y}$$ can be expressed as (6):
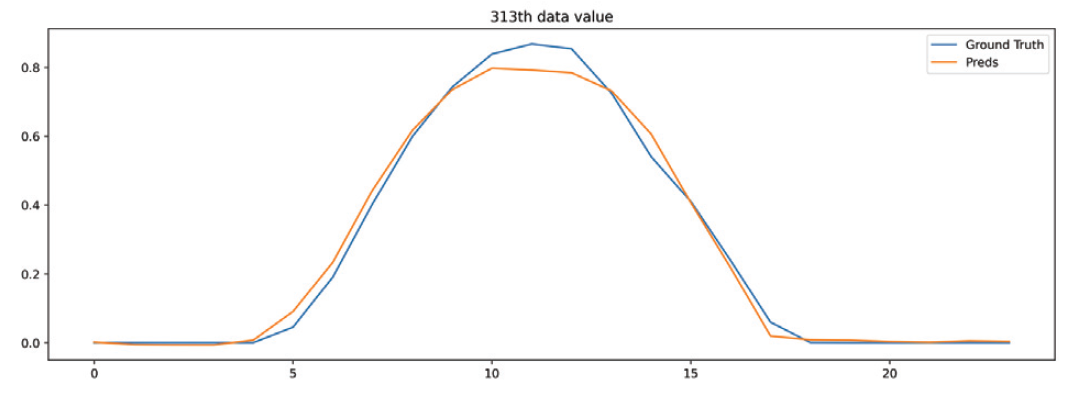
(6)[TeX:] $$\begin{aligned} & R M S E=\frac{1}{N} \sqrt{\sum_{i=1}^N\left(y_i-\hat{y}_i\right)^2} \\ & M A E=\frac{1}{N} \sum_{i=1}^N\left|y_i-\hat{y}_i\right| \\ & m M A P E=\left\{\begin{array}{l} \frac{100}{N} \sum_{i=1}^N\left|y_i-\hat{y}_i\right|, \text { if }|y|_{\max }\lt 1 \\ \frac{100}{N} \sum_{i=1}^N \frac{\left|y_i-\hat{y}_i\right|}{|y|_{\max }}, \text { else } \end{array}\right. \\ & R^2=1-\frac{\sum_{i=1}^N\left(y_i-\hat{y}_i\right)^2}{\sum_{i=1}^N\left(y_i-\bar{y}\right)^2} \end{aligned}$$5.3 Experimental ResultsThe quantitative comparison results with other models measured using test data are shown in Table 1. The comparison results show that the hybrid model proposed in this paper achieved the best results in all four metrics, and showed about 10% improved prediction quality compared to the single-structure model, proving the superiority of the proposed structure. In addition, as shown in the Fig. 7, the hybrid model’s predicted values and actual values were compared for arbitrary test data, and it was confirmed that it could generate predictions similar to the actual values. Table 1. Quantitative comparison results
5.4 Ablation StudyAdditionally, we conduct ablation studies to test the performance of different concatenation methods for different prediction lengths. Table 2 shows the performance changes by concatenation methods and prediction lengths. The common method of concatenating each output does not significantly improve performance because it does not extract valid features well, and it also increases complexity by doubling the number of dimensions. On the other hand, when concatenating based on self-attention techniques, it shows higher performance than a single model, proving that it is useful to reflect both trends and irregularities using the outputs of three models. Table 2. Ablation study on predict length and merging methods (NL: NLinear, DL: DLinear, MHA: Multi-Head Attention)
6. Future WorkFuture work could be conducted by extending the dataset to also include weather data and power generation data from power plants in other regions, both within Korea and maybe even beyond. The model could be extended to also accept positional information and with that spatially aware DL blocks, so that a single model could be trained to handle all the different locations, therefore training a model that could potently even, to some extend, generalize in a way where it can predict the power for new plants without additional training. Another possible future direction would be the attempt to predict even further into the future, a task that is not trivial by any means. One could, for example, consider utilizing real live weather forecast data to provide the model with more relevant and more reliable weather data for future timesteps, so that the results can be based on those. 7. ConclusionIn this study, we tackled the challenges of forecasting solar power generation, which is critical for the efficient use of renewable energy. We proposed a hybrid model that combines LSTM and linear models with a multi-head attention mechanism. This approach effectively captures both short-term variations and long-term trends in time series data, addressing the inherent unpredictability of renewable energy sources. Our experimental results show that the proposed model outperforms existing prediction models by approximately 10%, achieving an RMSE of 50.68, MAE of 26.12, mMAPE of 6.43, and an R2 value of 0.80. These metrics confirm the model's ability to deliver more accurate and reliable solar power forecasts compared to other methods. By improving prediction accuracy, this hybrid approach can enhance the integration of renewable energy into power grids, enabling better energy management and storage planning. BiographyHyeonseok Jinhttps://orcid.org/0009-0002-8271-6792 e-mail : ggyo003@jnu.ac.kr He received his B.S. degree in Computer and Information Engineering from Chonnam National University, in 2023. He is currently pursuing the M.S degree in AI Convergence at Chonnam National University. His research interests include AI, deep learning, spatiotemporal learning, time-series analysis. BiographyDavid J. Richterhttps://orcid.org/0000-0001-5413-6710 e-mail : david_richter@jnu.ac.kr He received the B.S. degree in computer science from Kempten University of Applied Sciences, in 2019, and the M.S. degree in computer information technology from Purdue University Northwest, in 2021. He is currently pursuing the master's degree in AI convergence with Chonnam National University. His research interests include AI, machine and deep learning, reinforcement learning, genetic programming. BiographyMD Ilias Bappihttps://orcid.org/0009-0000-7616-3074 e-mail : i_bappi@jnu.ac.kr He received his B.S. degree in Computer Science and Engineering from Daffodil International University, in 2017. He worked as a Software Engineer at Samsung Electronics, over five years until 2023. Currently, he is pursuing a master's degree in AI Convergence at Chonnam National University. His research interests including machine learning, deep learning, continual learning, and their applications in agriculture and healthcare. BiographyKyungbaek Kimhttps://orcid.org/0000-0001-9985-3051 e-mail : kyungbaekkim@jnu.ac.kr He received the B.S., M.S., and Ph.D. degrees in electrical engineering and computer science from Korea Advanced Institute of Science and Technology (KAIST), in 1999, 2001, and 2007, respectively. He is cur rently a Professor with the Department of AI Convergence, Chonnam National University. Previously, he was a Postdoctoral Researcher with the Department of Computer Sciences, University of California, Irvine. His research inter ests include intelligent distributed systems, SDN/SDI, big da ta platform, GRID/cloud systems, social networking systems, AI applied cyber-physical systems, blockchain, and other is sues of distributed systems. References
|
StatisticsCite this articleIEEE StyleH. Jin, D. J. Richter, M. I. Bappi, K. Kim, "Solar Power Generation Forecasting using a Hybrid LSTM-Linear Model with Multi-Head Attention," The Transactions of the Korea Information Processing Society, vol. 14, no. 2, pp. 123-133, 2025. DOI: https://doi.org/10.3745/TKIPS.2025.14.2.123.
ACM Style Hyeonseok Jin, David J. Richter, MD Ilias Bappi, and Kyungbaek Kim. 2025. Solar Power Generation Forecasting using a Hybrid LSTM-Linear Model with Multi-Head Attention. The Transactions of the Korea Information Processing Society, 14, 2, (2025), 123-133. DOI: https://doi.org/10.3745/TKIPS.2025.14.2.123.
TKIPS Style Hyeonseok Jin, David J. Richter, MD Ilias Bappi, Kyungbaek Kim, "Solar Power Generation Forecasting using a Hybrid LSTM-Linear Model with Multi-Head Attention," The Transactions of the Korea Information Processing Society, vol. 14, no. 2, pp. 123-133, 2. 2025. (https://doi.org/https://doi.org/10.3745/TKIPS.2025.14.2.123)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||